Integrate natif.ai processing into DocuWare via Make#
This Guide will demonstrate how to use Make.com for leveraging the power of our AI-powered document extraction system to augment your incoming invoice documents in DocuWare with accurate data extractions.
We'll start by creating a scenario to build the flow that will ingest documents, process them through natif.ai, and add to DocuWare.
natif.ai + DocuWare Template#
As a means of simplifying the process we created a template with the basic layout pre-configured. After connecting your natif.ai and DocuWare accounts, the template scenario is almost ready to successfully run. It will still be required to configure a mapping of tabular output from the natif.ai api to the DocuWare tray, but this guide will explain this procedure step by step.
How to build our Scenario#
Adding your data source#
To begin, our scenario will require some data source, for our purposes here we'll use an email watch trigger from the Email module provided by Make and configure it to watch our invoices folder.
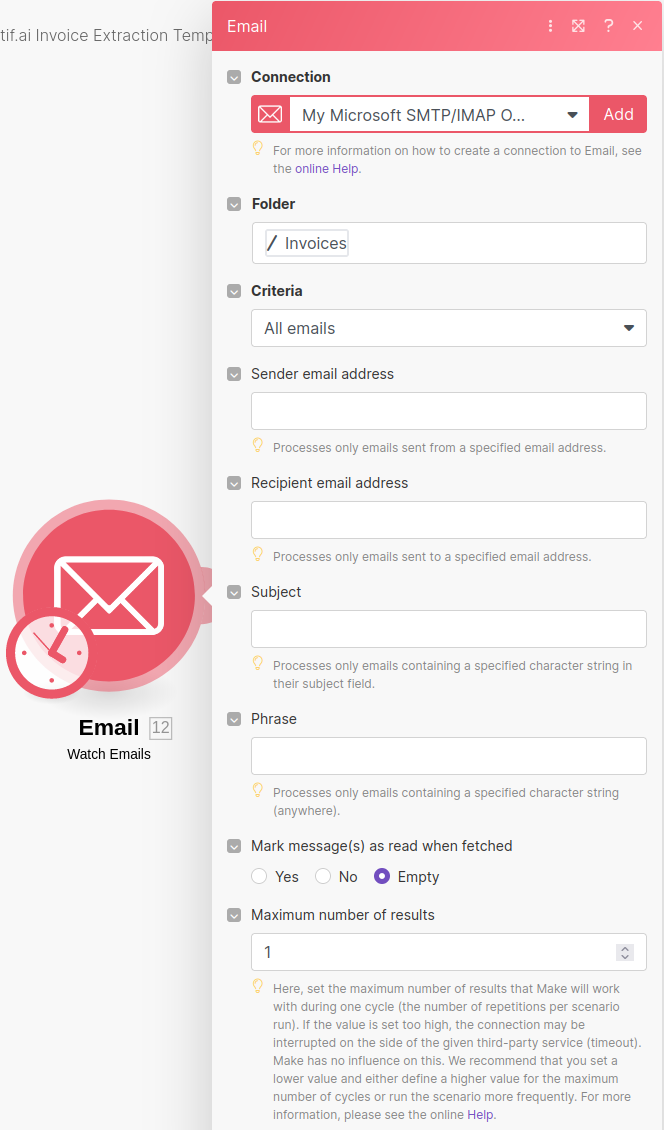
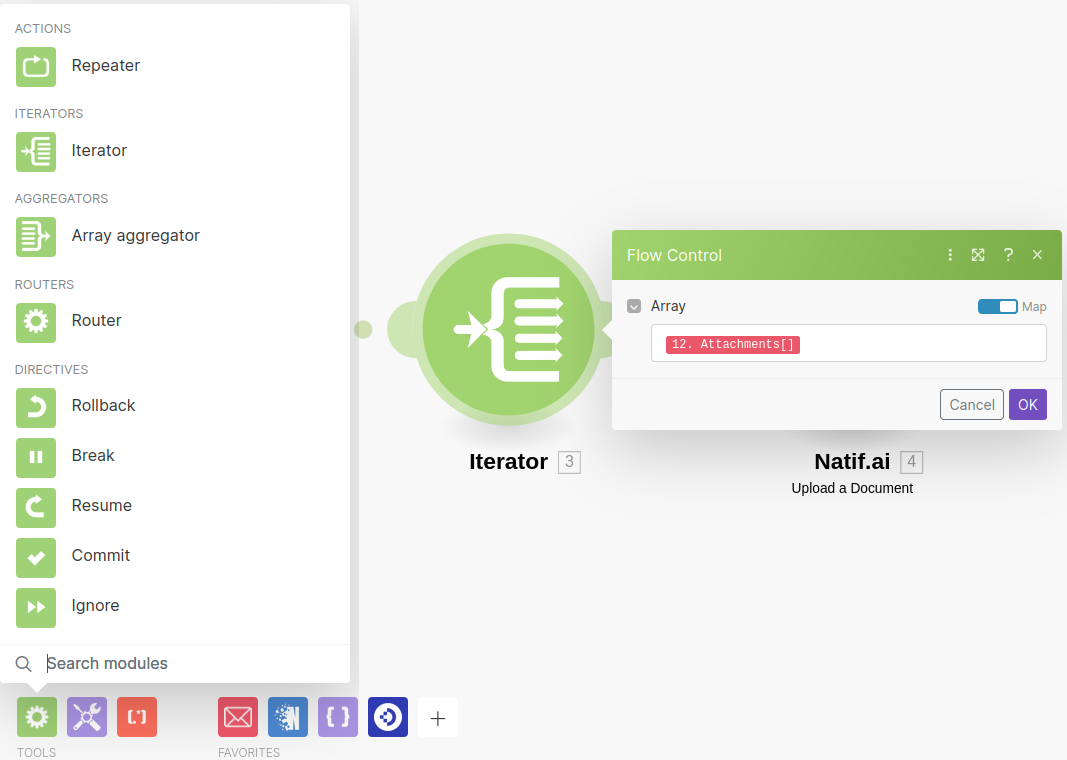
This trigger will run the scenario for every new mail item that arrives in our invoices folder, forwarding each mail bundle to the successive steps. What we want to process from each of these bundles, are the attachments on each email which contain our invoices. We can use the Make Iterator Node from the Flow Control Toolbox to process this attachment list and pass each of these files to the natif.ai extraction plugin one-by-one.
Additionally, as the tool group suggests, this will provide control over the rate at which you forward documents to the natif.ai api.
Connecting your natif.ai account#
Next we'll configure the natif.ai plugin by linking it to our account on <https://platform.natif.ai>.
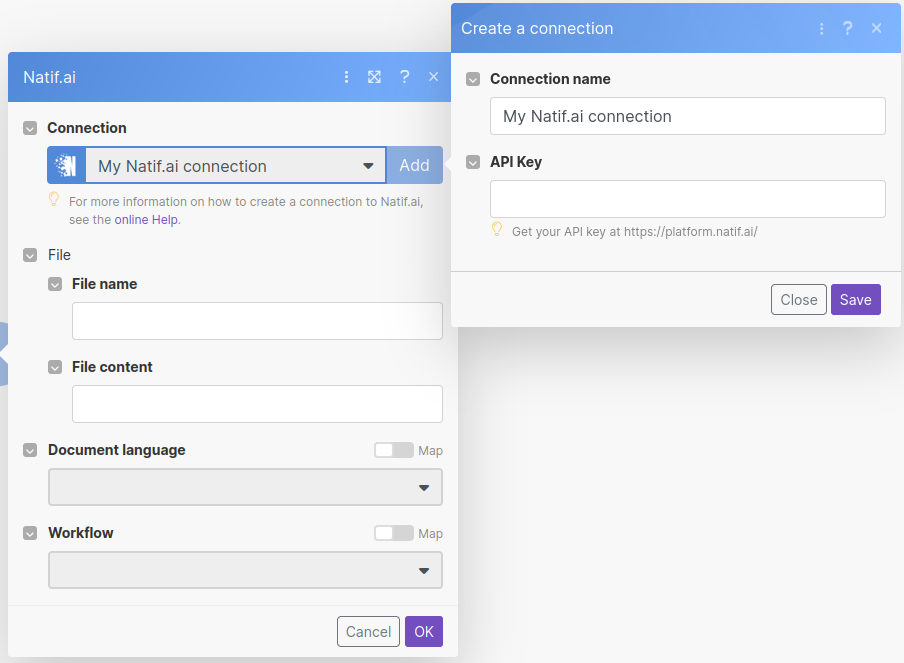
To do this we'll need an API key, you can find the steps needed for this here.
Handling processing output from natif.ai module#
We can then select the expected document language and the desired extraction API; for the purposes of this walkthrough we'll be using the Invoice Information Extraction API.
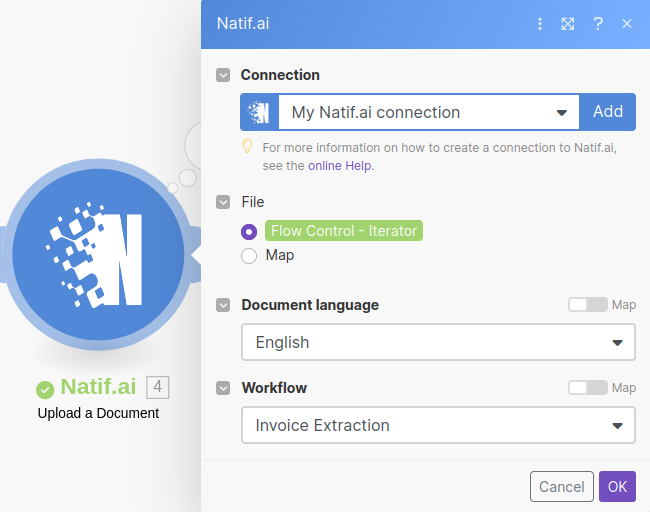
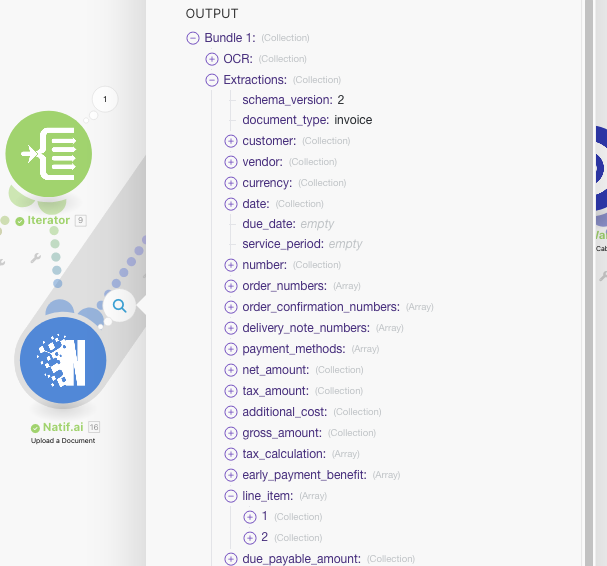
As an intermediate step, we'll need to process a valid document through the Make system. As our extraction structure is dynamic based on the extraction type, Make needs the output from a processed document to infer the output structure. Once the Make system understands the output data from the natif.ai api, we can use it as inputs for the succeeding Make steps. To do so, simply ensure an unread email that matches our configured trigger exists in the invoice folder and run the Make workflow once. The Email watcher will then select any unread emails and process the attached invoice files.
Great! Make has now inferred, how the invoice extraction data from natif.ai looks.
Connect natif.ai to DocuWare#
Finally, we import the invoice file together with the natif.ai extractions into DocuWare using DocuWare's own Make module.
How we connect our natif.ai module to the DocuWare module depends on what data we wish to extract. If only singular values are desired, we can link the natif.ai module directly to the DocuWare module and map values from the natif.ai module directly to DocuWare Dialog fields. In this case, we would like to also associate the the tabular listing of line items produced by the Invoice Information Extraction workflow. To provide this information in a convient bundle for the DocuWare module, we'll utilize a few additional modules, first to iterate over the Natif extraction data, and then to create a JSON string to be mapped to the DocuWare module.
The Iterator module is used to process each line item from our extraction and pass it on to the JSON Aggregator to be processed.
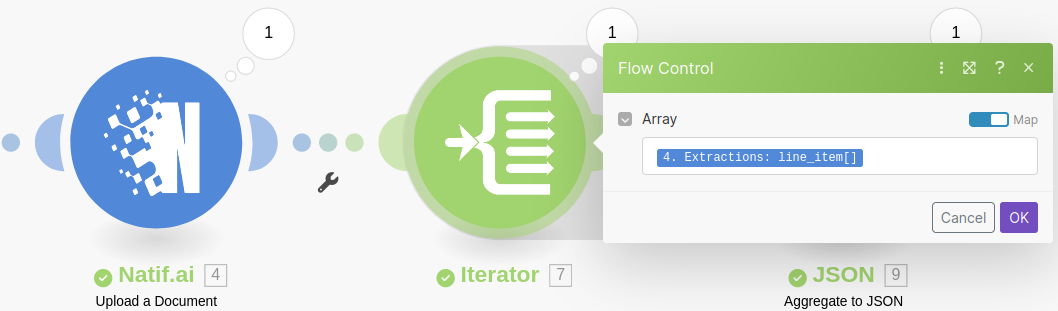
The Aggregate to JSON module from Make is used to transform the line items from an array of structured data to table information as a JSON string in a format that is understood by DocuWare, however as data from the module directly before the JSON Aggregation module is lost we'll want to ensure we reference the Iterator as the source.
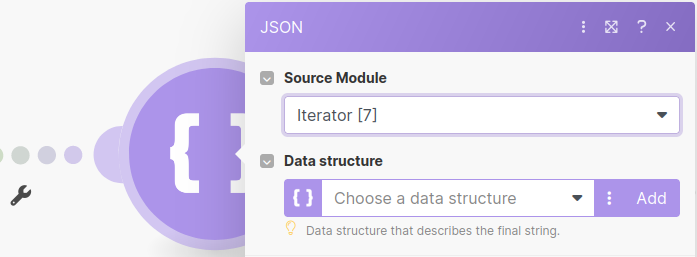
The data structure defined by the aggregator is what will be allow extraction information to be processed by the DocuWare system, thus it needs to reflect the column names and types as defined in your DocuWare field.
For a more in-depth discussion of this topic see here.
The JSON string produced can now be used directly in the Positionen field of the DocuWare Store to File Cabinet module to allow the extracted line_items to be attached as part of the invoice document to be uploaded.
Pass data from natif.ai module to DocuWare#
We now have all of the elements needed to map all of the extracted information from the natif.ai module to the DocuWare module. We'll use a Store To File Cabinet module as it supports the mapping of the JSON string we just created to our Positionen table field.
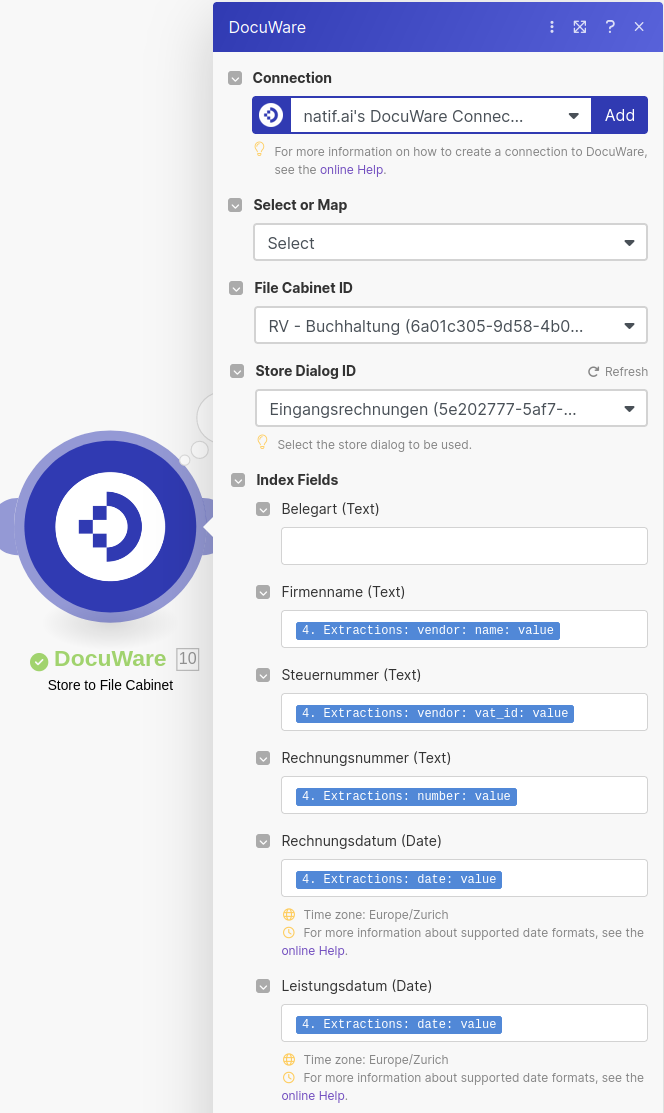
In the configuration window we will use the Select option rather than map as this will allow use to select our Storage Dialog ID from our DocuWare account. We'll then need to map the fields extracted by the natif.ai system to values understood by the Storage Dialog.
In our example, we're storing to the Eingangsrechnungen Storage Dialog, as such we map the value field of the name field held under vendor of our Extraction information to our Storage Dialog's Firmenname, the value field of the vat_id field held under vendor of our Extraction information to our Storage Dialog's Steuernummer, etc.
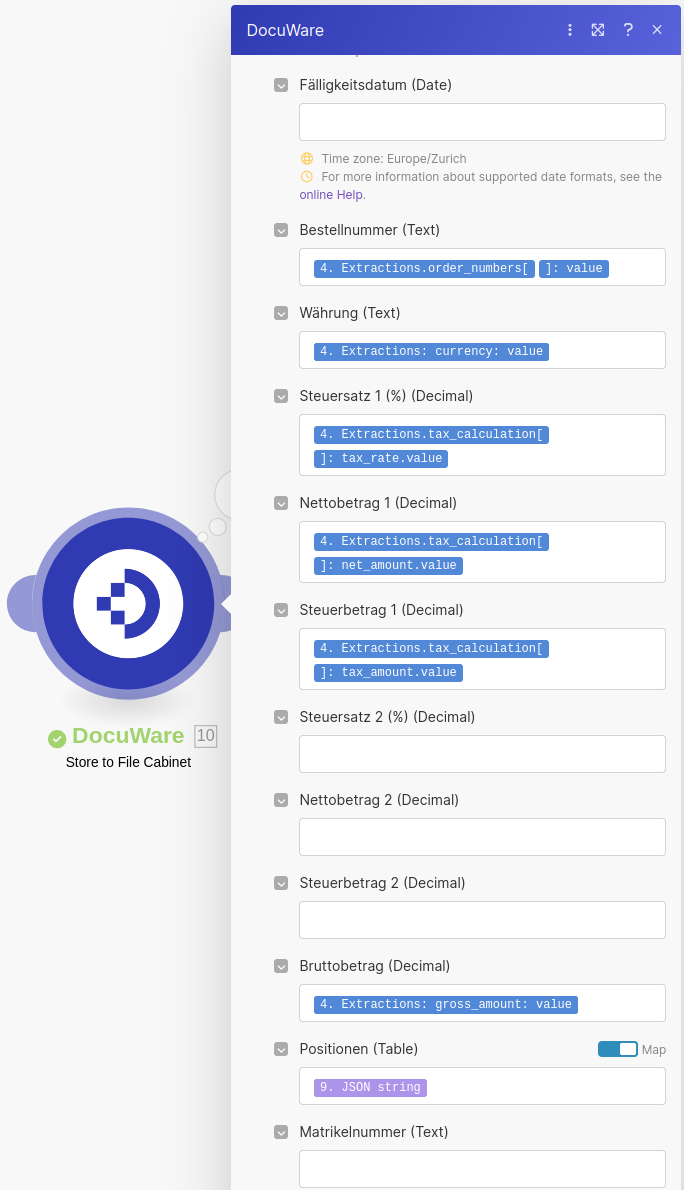
Note: it is not advised to make any fields which may be mapped to an extraction field required. Since the data extracted is transient and may not always be present in every extraction, your workflow may break if you make such fields required.
For more information about the various fields in Extraction, and other response structures, you can vist the developer documentation.
We have now uploaded our document and applied the various extracted data as index fields on the document in DocuWare, however as we used Store to File Cabinet to perform this action the document is not in our document tray for review where we want it. To achieve this we will use the Transfer a Document module of the DocuWare app.
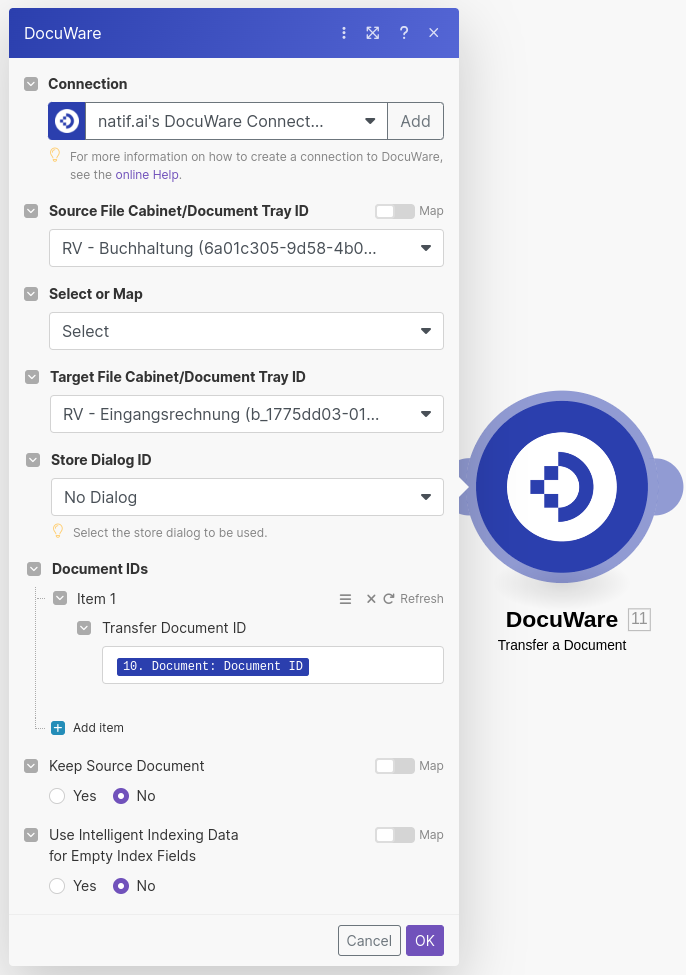
The important fields to note are the Source File Cabinet ID, which would match the File Cabinet used in the Store to File Cabinet module, and the Target Document Tray ID.
Hint: If your DocuWare account has a number of File Cabinets and Document Trays where the names are the same, a useful trick to differentiate them is that most document tray ids are prefixed with b_
Finally we will need to map the Document ID, returned during the Store to File Cabinet phase, to the Document IDs section.
Finished#
Your Make workflow, integrating our natif.ai api and DocuWare, is now ready to be used. To test it simply run the scenario, send any number of invoice documents to your Webhook email address, and observe your DocuWare tray.